SEO 优化
背景
在搜索引擎网站的后台会有一个非常庞大的数据库,里面存储了海量的关键词,而每个关键词又对应着很多网址,这些网址是被“网络爬虫”程序(又叫“搜索引擎蜘蛛”)从茫茫互联网中下载收集而来的。
随着各种各样网站的出现,爬虫程序每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析提炼,找到其中的关键词,如果爬虫认为关键词词在数据库中没有,但对用户是又有用的,便存入后台的数据库中。
反之,如果爬虫认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新的、有用的信息保存起来提供用户搜索。
当用户搜索时,就能检索出与关键字相关的网址显示给访客。
一个关键词对用多个网址,因此就出现了排序的问题。相应地,当与关键词最吻合的网址就会排在前面了。
在爬虫抓取网页内容,提炼关键词的这个过程中,就存在一个问题:爬虫能否看懂。
如果网站内容是 flash 和 js 等,那么它是看不懂的,会犯迷糊,即使关键字再贴切也没用。
相应的,如果网站内容可以被搜索引擎能识别,那么搜索引擎就会提高该网站的权重,增加对该网站的友好度。
这样一个过程我们称之为 SEO。
分析
概念
SEO(Search Engine Optimization),即搜索引擎优化。
SEO 是随着搜索引擎的出现而来的,两者是相互促进,互利共生的关系。
目的
提升网站在搜索引擎中的权重,增加对搜索引擎的友好度,使得用户在访问网站时能排在前面。
分类
白帽 SEO
通过对网站结构、性能、以及页面代码方面的优化,使网站对搜索引擎和用户更加友好,起到了改良和规范网站设计的作用,并且网站也能从搜索引擎中获取合理的流量,这是搜索引擎鼓励和支持的。
黑帽 SEO
利用和放大搜索引擎政策缺陷,来获取更多用户的访问量,这类行为大多是欺骗搜索引擎,一般搜索引擎公司是不支持与鼓励的。
优化方向
对网站的标题、关键字、描述精心设置,反映网站的定位,让搜索引擎明白网站是做什么的。
优化内容与关键字的对应,增加关键字的密度。
在网站上合理设置 Robots.txt 文件。
生成针对搜索引擎友好的网站地图。
增加外部链接,到各个网站上宣传。
前端是构建网站中很重要的一个环节,前端的工作主要是负责页面的 HTML + CSS + JS,优化好这几个方面会为 SEO 工作打好一个坚实的基础。
前端 SEO 优化措施
网站结构优化
一般而言,建立的网站结构层次越少,越容易被爬虫抓取,也就容易被收录。
控制首页链接数量
网站首页是权重最高的地方。
如果首页链接太少,没有“桥”,爬虫不能继续往下爬到内页,直接影响网站收录数量。
但是首页链接也不能太多,一旦太多,没有实质性的链接,很容易影响用户体验,也会降低网站首页的权重,收录效果也不好。
扁平化目录
一般中小型网站目录结构超过 3 级,爬虫便不愿意往下爬了。
并且如果访客经过跳转 3 次还没找到需要的信息,很可能离开。
尽量让爬虫只要跳转 3 次,就能到达网站内的任何一个内页。
导航优化
尽量采用文字方式,也可以搭配图片导航,但是图片代码一定要进行优化,标签必须添加“alt”和“title”属性,告诉搜索引擎导航的定位,做到即使图片未能正常显示时,用户也能看到提示文字。
在每一个网页上应该加上面包屑导航。
- 从用户体验方面来说,可以让用户了解当前所处的位置以及当前页面在整个网站中的位置,帮助用户很快了解网站组织形式,从而形成更好的位置感,同时提供了返回各个页面的接口,方便用户操作
- 对爬虫而言,能够清楚的了解网站结构,同时还增加了大量的内部链接,方便抓取,降低跳出率。
页面布局优化
头部
logo 及主导航,以及用户的信息。
主体
左边正文,包括面包屑导航及正文。右边放热门文章及相关文章。
目的:
- 留住访客,让访客多停留。
- 对爬虫而言,这些文章属于相关链接,增强了页面相关性,也能增强页面的权重。
底部
版权信息和友情链接。
重要代码放最前
搜索引擎抓取 HTML 内容是从上到下,利用这一特点,可以让主要代码优先读取,广告等不重要代码放在下边。
例如,在左栏和右栏的代码不变的情况下,只需改一下样式,利用 float:left; 和 float:right; 就可以随意让两栏在展现上位置互换,这样就可以保证重要代码在最前,让爬虫最先抓取。同样也适用于多栏的情况。
控制页面大小
一个页面最好不要超过 100k,太大的话页面加载速度会变慢。
当速度很慢时,用户体验不好,留不住访客,并且一旦超时,爬虫也会离开。
页面代码优化
突出重要内容
标题
title 标签:只强调重点即可,尽量把重要的关键词放在前面,关键词不要重复出现,尽量做到每个页面的 <title> 标题中不要设置相同的内容。
关键词
keywords:关键词,使用英文逗号隔开,列举出几个页面的重要关键字即可,切记过分堆砌。
页面描述
description:页面描述,需要高度概括网页内容,切记不能太长,过分堆砌关键词,每个页面也要有所不同。
语义化
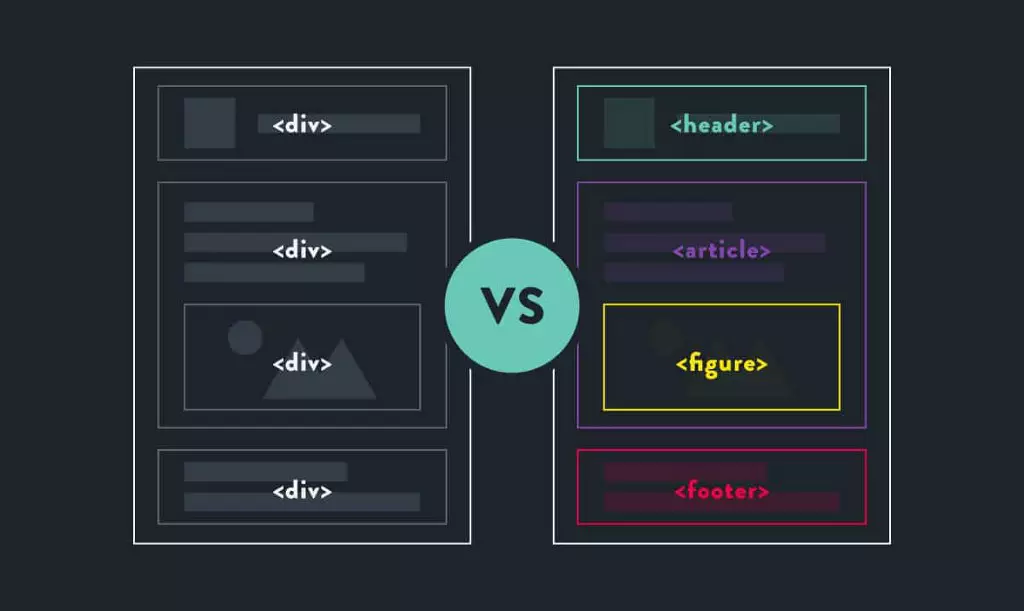
语义化书写 HTML 代码,符合 W3C 标准。
尽量让代码语义化,在适当的位置使用适当的标签,用正确的标签做正确的事。
让阅读源码者和爬虫都一目了然。
比如:h1- h6 用于标题类,nav 标签用来设置页面主导航,列表形式的代码使用 ul 或 ol,重要的文字使用 strong 等。
链接规范化
页内链接添加 title 属性加以说明。
外部链接加 el="nofollow" 属性,告诉爬虫不要去,因为一旦爬虫爬了外部链接,就不会再回来了。
h 标签
h1 标签自带权重,一个页面有且最多只能有一个,是该页面最重要的标题。没有标题就放 logo。
从 h1 开始逐级往下添加,合理使用 h 标签能使页面结构更加清晰、层次更加完备。
alt 属性
图片添加 alt 属性,当网络速度很慢,或者图片地址失效时, alt 属性可以让用户知道这个图片的作用。
同时为图片设置高度和宽度,可提高页面的加载速度。
其他
表格应该使用表格标题标签:caption 元素定义表格标题。caption 标签必须紧随 table 标签之后。
重要内容不要用 js 输出:爬虫不会读取 js 里的内容,所以重要内容必须放在 HTML 里。
少使用 iframe 框架:爬虫一般不会读取其中的内容。
谨慎使用 display:none 属性:对于不想显示的文字内容,应当设置 z-index 或缩进设置成足够大的负数偏离出浏览器之外。因为搜索引擎会过滤掉 display:none 其中的内容。
网站性能优化
减少 http 请求数量
在浏览器与服务器进行通信时,主要是通过 HTTP 进行通信。浏览器与服务器需要经过三次握手,每次握手需要花费大量时间。
而且不同浏览器对资源文件并发请求数量有限(不同浏览器允许并发数),一旦 HTTP 请求数量达到一定数量,资源请求就存在等待状态,这是很致命的,因此减少 HTTP 的请求数量可以很大程度上对网站性能进行优化。
CSS Sprite:将多张图片合并成一张图片达到减少 HTTP 请求的一种解决方案,可以通过 CSS 的 background 属性来访问图片内容。这种方案同时还可以减少图片总字节数。
合并 css 和 js 文件:使用工程化打包工具如:grunt、gulp、webpack,在发布前将多个 css 或者多个 js 合并成一个文件。
采用 lazyload:懒加载,网页上的内容在一开始无需加载,不需要发请求,等到用户操作真正需要的时候立即加载出内容。这样就控制了网页资源一次性请求数量。
控制资源文件加载优先级
浏览器在加载 HTML 内容时,是将 HTML 内容从上至下依次解析,解析到 link 或者 script 标签就会加载 href 或者 src 对应链接内容,为了第一时间展示页面给用户,就需要将 CSS 提前加载,不要受 JS 加载影响。
一般情况下都是 CSS 在头部,JS 在底部。
结构行为样式相分离
尽量外链 CSS 和 JS,保证网页代码的整洁,也有利于日后维护。
浏览器缓存
将网络资源存储在本地,等待下次请求该资源时,如果资源已经存在就不需要到服务器重新请求该资源,直接在本地读取该资源。
减少重排
基本原理:DOM 的变化影响到了元素的几何属性(宽和高),浏览器会重新计算元素的几何属性,会使渲染树中受到影响的部分失效,浏览器会验证 DOM 树上的所有其它结点的 visibility 属性。
如果 reflow 的过于频繁,CPU 使用率就会急剧上升。
减少 reflow,如果需要在 DOM 操作时添加样式,尽量使用增加 class 属性,而不是通过 style 操作样式。
其他
减少 DOM 操作
使用 CDN 网络缓存:加快用户访问速度,减轻服务器压力。
启用 GZIP 压缩:浏览速度变快,搜索引擎的爬虫抓取信息量也会增大。
伪静态设置:如果是动态网页,可以开启伪静态功能,让爬虫“误以为”这是静态网页,因为静态网页比较合爬虫的胃口,如果 url 中带有关键词效果更好。
 微信
微信- 支付宝